Multi-FPGA

“Build Server Infrastructure
for Datacenters”
Cloud computing is rapidly changing how enterprises run their services by offering a virtualized computing infrastructure over the internet. Datacenter is a powerhouse behind cloud computing, which physically hosts millions of computer servers, communication cables, and data storages. Recently, as the number of services using AI in data centers is increasing, high-efficiency systems that exceed existing systems are needed. To address this challenge, the datacenters are trying to implement multi-FPGA appliance for accelerating services.
In Multi-FPGA research, we aim to develop a multi-FPGA server infrastructure that not only accelerates datacenter services but also provide solutions for customized system design. The FPGA-based accelerator provides fully reprogrammable hardware to support new operations and larger dimensions of evolving services with minimum cost for redesign when compared to an ASIC-based accelerator. The FPGA-based accelerator also has significantly lower total cost of ownership due to relatively low device and power cost when compared to a GPU-based accelerator.
Multi-FPGA System for Accelerating Large-Language-Model
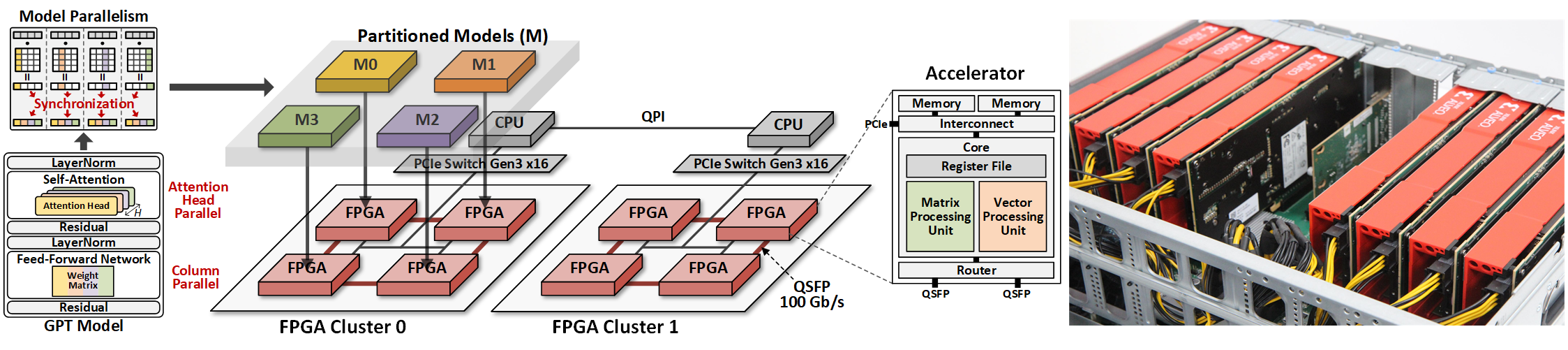
Transformer is a deep learning language model widely used for natural language processing (NLP) services in datacenters. Among transformer models, Generative Pretrained Transformer (GPT) has achieved remarkable performance in text generation, or natural language generation (NLG), which needs the processing of a large input context in the summarization stage, followed by the generation stage that produces a single word at a time. The conventional platforms such as GPU are specialized for the parallel processing of large inputs in the summarization stage, but their performance significantly degrades in the generation stage due to its sequential characteristic. Therefore, an efficient hardware platform is required to address the high latency caused by the sequential characteristic of text generation
DFX, a multi-FPGA acceleration appliance that executes GPT-2 model inference end-to-end with low latency and high throughput in both summarization and generation stages. DFX uses model parallelism and optimized dataflow that is model-and-hardware-aware for fast simultaneous workload execution among devices. Its compute cores operate on custom instructions and provide GPT-2 operations end-to-end. DFX achieves 5.58× speedup and 3.99× energy efficiency over four NVIDIA V100 GPUs on the modern GPT-2 model. DFX is also 8.21× more cost-effective than the GPU appliance, suggesting that it is a promising solution for text generation workloads in cloud datacenters.